The ipa-sql schema defines the tables, indices, and stored procedures for accessing IPA data.
The schema requires PostgreSQL 9.0 or later, with the IP4R extension installed.
Design
The IPA data model maps IP address ranges to any number of user-defined attributes. Because these attribute mappings often change over time, IPA allows users to associate groups of these mappings with a specific time period. This facilitates retrospective analysis of network data based on how addresses were labeled during the time period in question.
Here is the entity-relationship diagram for IPA.
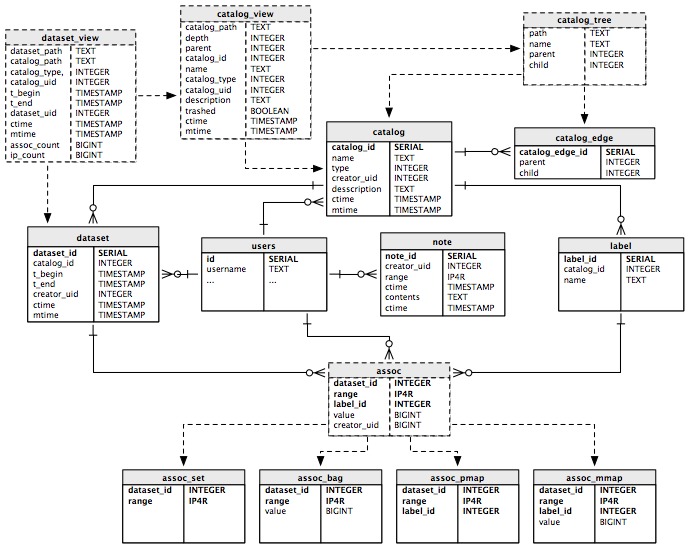
Within an IPA data store, addresses and labels are grouped into logical partitions called catalogs. Within each catalog, clients import one or more datasets, which are collections of IPA records that are valid during a given time period. Each of these datasets contains one or more associations, which are the observed IP addresses, along with any labels or values, depending on the catalog type.
IPA supports the following catalog types:
- set - simply a set of IP addresses or ranges
- bag - a set of IP addresses, each associated with a numeric value
- prefix map - a mapping of addresses to textual labels
- multimap - a mapping of addresses and labels to numeric values
The assoc table pictured above is actually an updateable view, not a physical table. Data logically added to the assoc view will be inserted into either the assoc_set, assoc_bag, assoc_pmap, or assoc_mmap tables, depending on the structure of the data itself.
Installation
Follow these steps to get the schema loaded into a PostgreSQL 9.0 or later database server. The following instructions assume you're using the default superuser named postgres to create the database and execute priveleged commands.
The IPA database schema requires the IP4R extension to PostgreSQL. Installation instructions are in the README.ip4r file included in the IP4R distribution.
After this extension is installed on the database server, create the IPA database with the following command:
$ psql -U postgres postgres < ipa-create.sql
This will create the IPA database, schema, and administrative user. You can change the names of any of these database objects, but if you do, you must also change those names in the other schema files you'll be loading in the following steps. You will probably also want to give the IPA administrative user (default username ipa) a password here, in which case, you'll need to provie this password for authentication below.
At this point, you can import the IP4R extension into the database with the following command (assuming the name of your IPA database is "ipa", and PostgreSQL is installed in $PGDIR:
$ psql -U postgres -f $PGDIR/contrib/ip4r.sql ipa
Next, you need to run a few SQL commands as the Postgres super-user. These commands are contained in the file ipa-schema-privileged.sql:
$ psql -U postgres ipa < ipa-schema-privileged.sql
Now you can load the main IPA schema with the following command:
$ psql -U ipa ipa < ipa-schema.sql
At this point, you should have a working IPA database.
Auditing
By default, auditing will be enabled for all tables in the database. This will insert a record in the audit log tables for every insert, update, and delete. As this will certainly have an impact on performance, you may disable auditing on any table by executing the following from a psql prompt:
SELECT ipa_enable_audit('tablename', FALSE);
replacing tablename with the name of the table for which you wish to disable audit logging.
