What is YAF?
Yet Another Flowmeter (YAF) is a sensor that captures traffic on a network, either live or from PCAP files. It generates flow data - which contains information about each connection observed on a network - from a stream of observed packets. YAF examines packet payloads, captures useful information for specific protocols, and exports it in a protocol-specific template – a process known as deep packet inspection (DPI). YAF complies with the IPFIX standard.
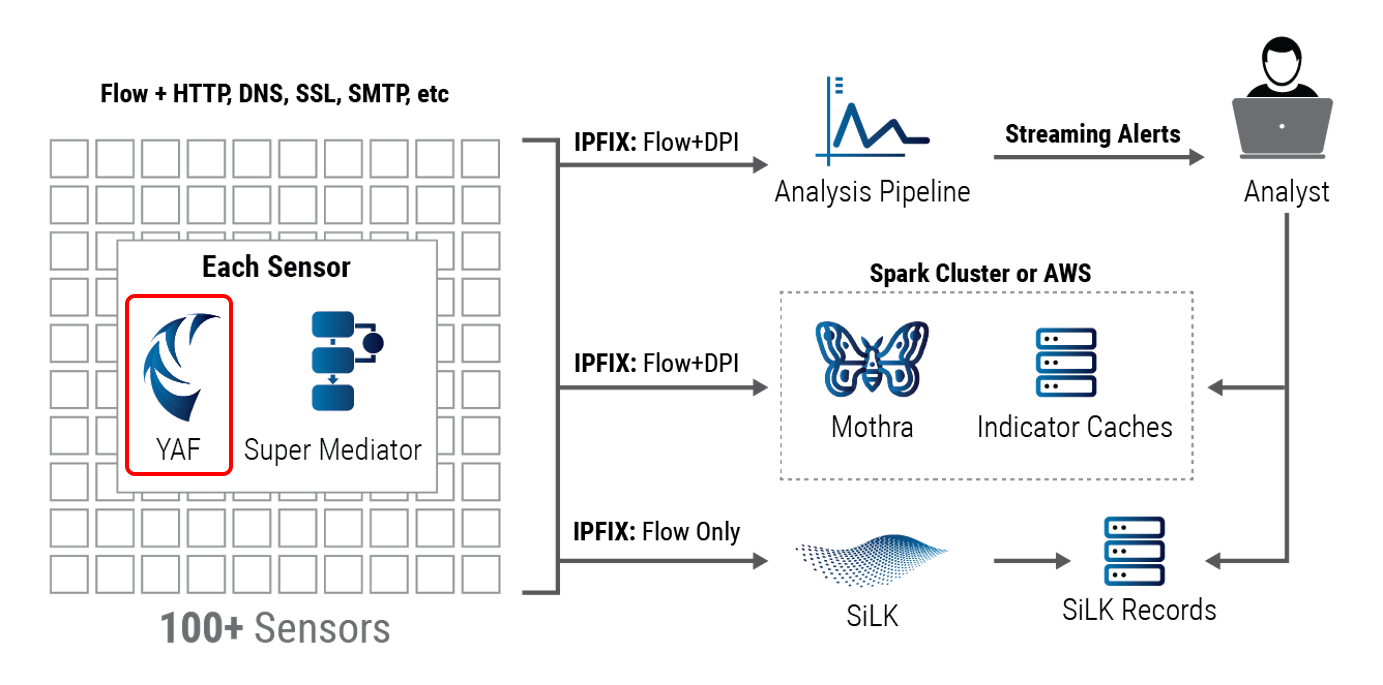
YAF's Role in the CERT NetSA Security Suite
YAF is the data collection component of the CERT NetSA Security Suite. Its purpose is to turn packets into network flows to be processed by downstream tools such as Analysis Pipeline, SiLK, and Mothra. This is an essential part of the network monitoring and analysis functions provided by the CERT NetSA tool suite.
Recommended Uses of YAF
Overview
YAF was originally intended as an experimental implementation tracking developments in the IETF IPFIX working group, specifically bidirectional flow representation, archival storage formats, and structured data export with Deep Packet Inspection (DPI). It is designed to perform acceptably as a flow sensor on any network on which white-box flow collection with commodity hardware is appropriate. YAF can and should be used on specialty hardware when scalability and performance are of concern.
With the original intention as context, there are several modern applications of YAF, either dealing with data fed from a live network or from a collection of already-captured packets. In the current tool suite, YAF has become the principle, but not only, tool for dealing with packet data. YAF’s applications include:
- Building flow records
- Building flow records with DPI fields
- Building an index of flow records
- Indexing packet capture files with metadata
- Building Packet-per-flow records
Building Flow Records
YAF’s first and principle function is generating flow records, especially supportive of assuring availability, performance, and security. YAF outputs flows in IPFIX format, using templates appropriate to the data. It can receive input from a live network or PCAP files. Flow records use a binary format, so they are much smaller than full packet captures or textual representations of the data. The process of generating flows extracts security-relevant fields but discards most or all of the packet data, both improving data privacy and reducing storage requirements. Since they mainly aggregate header information, flow records are largely unaffected by use of TLS or other encrypting protocols, allowing analysis without breaking encryption.
Applying YAF to build records enables analysis with flow tool suites including SiLK and Analysis Pipeline, extracts relevant fields, and summarizes traffic across long durations or large network infrastructures. Operators of large networks my conserve storage by converting flow records to the more compact SiLK binary format.
Building records from a live network
Placement of YAF processes as sensors on backbone routers or border routers provides for generation relevant to external threats or to disruption of traffic patterns, but will not normally generate records that allow full characterization of a specific host or device. Placing a sensor within subdomains allows for more targeted and detailed behavior observation of traffic to hosts or devices within those domains. While address translation or gateway processing may make matching of flows between the subdomains difficult, the gain in characterization within a domain may well be worthwhile. Lastly, placing a sensor outside the organization’s boundary may be important to assess the organization’s network footprint, performance, and availability for traffic to important external networks.
The flexibility of YAF in supporting these varied placements, and its efficiency in flow generation supports collection across a variety of networks. YAF is configurable to suit the placement, and to identify the sensor generating the flow records. There are even features, specifically observation domains, to record the sensor’s location.
Flow generation can be implemented on standalone devices or in-line on packet forwarding devices, such as routers. In either case, the sensor needs to be placed where traffic is broadcast or spanned between hosts to reduce traffic loss. YAF can also be placed on specific servers for targeted collection. YAF itself runs very efficiently, with successful placement having been made on low-end single-board computers for collection on very small, or light-traffic networks. More typically, the measurement devices will be either conventional or special-purpose devices.
Building records from PCAP
YAF can be used on previously-captured packets, PCAP files to generate records. These records will the same as if those packets were collected from a live network. These records are most often for retrospective analysis of an event or condition. Generating flow records from packet data permits summarization of the interactions and isolation of threatening or problematic traffic. This is commonly done on a dedicated analysis host, with sufficient storage to store the packets. The flow data itself is typically small enough not to overstress moderately-priced storage, given the relatively huge size of the packet captures. YAF’s rapid processing facilitates its use on moderate-to-large collections of packets. In a single run, YAF can process a series of PCAP files. Once the records are generated, the analysis tools can profile or summarize the traffic present, rapidly analyzing the event or condition.
Building Flow Records with DPI Fields
While generating flows, YAF examines packet payloads, captures protocol-specific information, and organizes it for export in protocol-specific templates attached to the flows. These protocol-specific fields are for application-level protocols (e.g., DNS, SSL, HTTP(S), SMTP) rather than for the transport-level protocols (e.g., TCP, UDP, ICMP) information captured in the main template for the flow. Capture of these fields is dependent on identifying the application-level protocol via the application labeling process, using either a regular expression or a specialized plug-in. If YAF doesn’t recognize the protocol or application labeling is not enabled, it will not generate DPI fields. By generating these fields explicitly, YAF makes them available for improved filtering and matching and for archiving to use in later trending and analysis.
One common use of the DPI fields is for more accurate filtering and matching of network traffic. By filtering on these fields, analyses (whether streaming using tools such as Analysis pipeline or retrospective using tools such as the SiLK suite) can exclude traffic unrelated to the event or condition being examined. As an example, matching a specific domain within a captured URL field for web traffic is likely to be more precise than matching an IP address for the web server, since such servers can support large numbers of domains. By excluding flows with irrelevant URLs, the analysis can more clearly isolate characteristics of the traffic.
Another common use of the DPI fields is to populate repositories or databases for later trending and analysis. For example, a data base of DNS resolutions, recorded with time and capture location facilitates understanding of domains that change resolution, which factors into a variety of analyses. A data base of SSL certificates may be useful to identify certificate reuse attacks, or other threats. As YAF attaches these DPI fields to output flows, SuperMediator can process them for their final storage location. During the data ingest, some installations construct DPI caches to more quickly determine the presence of indicators, allowing analysts to avoid full-repository searches for those fields.
Building An Index of Flow Records
To characterize the impact of traffic on a network, an analyst needs to be able to track its traversal of the network. There may also be need to assess how much traffic traverses unexpected or uninstrumented network paths. For complex network architectures, or large networks, traffic may traverse several links and virtual networks (VLANs) from source to destination. The sensors on links and VLANs may separately record this traffic several times. Analysts can characterize the traffic on these links by generating summary information about the flows generated may help to identify repeated captures of the same traffic. This summary information, referred to as metadata, consists of a series of lines recording flow key hash, start time to the millisecond, and capture file name. The metadata provides a small text summary of each flow, in effect, providing an index of which flows appear and where they appear. The flow key hash is a cryptographic hash value generated from the source and destination IP addresses, source and destination ports, protocol, and VLAN identifier. If a flow is present in more than one capture file, there will be multiple lines with the same flow key hash and start time. It is not possible for more than one flow to have the same key hash and start time pair.
As YAF is reading or writing packet capture files during its flow generation, it has the capability to record metadata for the flows generated from each such file. A given capture file may have many flows within it, so its corresponding metadata file will have many lines of data. Using rapid text search tools, such as fgrep, it is possible to rapidly identify the flows of interest and associate them with the point of capture.
There are several ways that this metadata can be used. First, it can help to rapidly identify flows that are generated at multiple points in the infrastructure (e.g., by sorting on the flow key hash and identifying flows with common hashes). Second, it can be used to index and filter packet captures (see the next section). Third, it can be used to identify incomplete flow metering, where expected flows are not generated (e.g., by isolating flows that should be redundantly generated, calculate the flow hash keys, and then compare against the actual generation). The compactness of the metadata facilitates rapid processing.
Indexing Packet Capture Files
In general, working with large packet capture files is difficult. Isolating traffic of interest and characterizing the hosts involved is an extended process with a variety of tool suites. The YAF suite, coupled with SiLK analysis tools, offers options to reduce this difficulty and rapidly both isolate traffic and characterize hosts, and also to specifically identify the packets involved.
First, YAF can split capture files by using the --pcap and --max-pcap parameters. If YAF is simultaneously generating a metadata file, it will insert the file name of the appropriate split into that file. Once the flow records are generated and converted for use by SiLK, they can be filtered to isolate the flows of interest. The corresponding flow key hashes can then be recalculated, and matched against the flow key hashes for the split capture files to isolate the packets of interest.
Second, if YAF isn’t used to split capture files or a metadata file, the output flow records can be converted and filtered through the SiLK suite to isolate flow records of interest, and then the flow key hashes and millisecond start times for those records can be calculated, and YAF run a second time over the input packet captures, this time filtering for packets that form flows matching those metadata entries. This process involves storing less data, but will likely be somewhat slower than calculating the metadata and producing split capture files.
Once the packets of interest are identified, they can be examined and further filtered using conventional packet analysis tools.
Building Packet-per-Flow Records
YAF can be used to convert each observed packet into a single-packet flow. These flows would have limited DPI fields, since application labeling would only apply to a single packet, and only if that packet’s data contained enough information for labeling. The flows would not aggregate information across packets. The total number of flows may get to be quite large, but the storage size will be smaller than for a packet capture. The advantage of this format is that it preserves the per-packet volume and timing information. This information can be useful in a variety of analyses, including:
- Identification of covert timing channels: generate the single-packet flow records, then examine the inter-packet arrival time for flows with common flow key hashes. If the packets are being manipulated for signaling, statistical distribution of these times should be bimodal (since timing channels often send binary values). If such traffic recurs between the same endpoints, there may well be a covert timing channel in use.
- Characterization of tunneled or encrypted traffic: generate both single-packet and conventional flow records, then use the application labeling in the conventional flow records to identify tunneling protocols. Calculate the flow key hash from the conventional flow records for the suspected tunneling, and also for the single-packet flow records. Match the flow key hashes, then use the single-packet flow records to examine per-packet byte volumes and inter-packet arrival times, which may be used to characterize the traffic as interactive, autonomic, data transfer, or keep-alive traffic.
- Detection of session hijacking attempts: generate the single-packet flow records, then use the flow key hashes to identify connections where there is a significant shift in behavior, such as short-command followed by data transfer, or data transfer followed by interactive commands. One method for such identification is based on per-packet byte volumes and inter-packet arrival times.
- Isolation of timing attacks, such as anticipatory TCP attacks: generate the single-packet flow records, then look for blocks of flows that acknowledge traffic before it is received, or that continue apparently-terminated flows, or match some other indicator of timing attacks.
While these brief examples explore only a few possibilities, there are other useful methods that build off knowing the per-packet characteristics of the data, while retaining the generality and storage savings of flow.
